
Self-Service Data Provisioning and Preparation in Data Lakes
- Date: 15.10.2021
-
With the ongoing trend of building central data lakes in enterprises, it is unclear how data is replicated from source systems. Often, data analysts have to rebuild SAP transactions to analyze data from the central data lake. In doing so, they must identify column names from SAP in the data lake and join tables. However, they do not know the logic of the underlying SAP transactions, nor have the technical skills to implement the required queries in the data lake. With this in mind, we designed and implemented a system – the REDLake Data Explorer – that makes queries from expert users available. Data analysts can search for queries by specifying the technical column names, column descriptions, or table names. Additionally, data analysts can investigate join possibilities through a network graph.
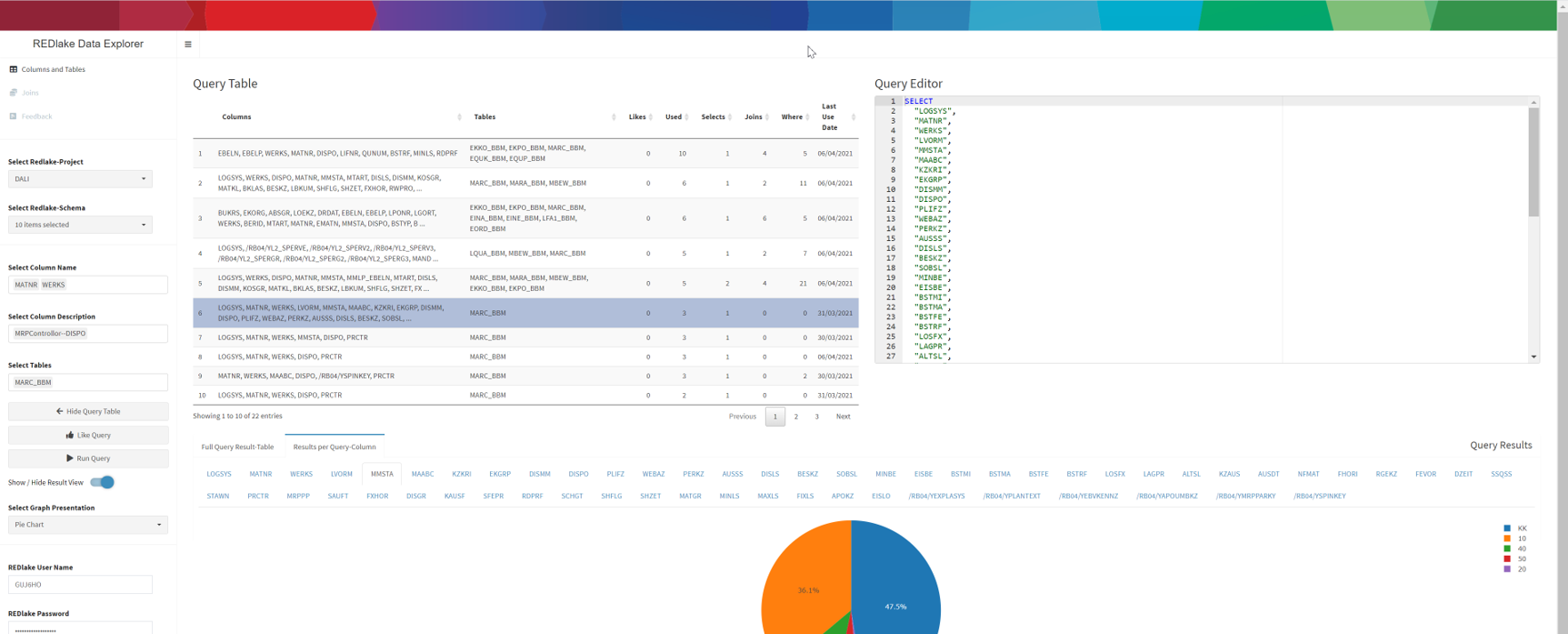
In the columns and tables view, data analysts can search for queries by specifying technical column names, column descriptions, or tables potentially relevant for their use case.
 In the join view, data analysts can investigate how tables can be joined for their use case by specifying tables or exploring the join graph.
In the join view, data analysts can investigate how tables can be joined for their use case by specifying tables or exploring the join graph.